算想云使用案例
案例1 使用私有数据集微调模型
案例1 是用户常见的微调场景,使用公开或私有数据集对开源大模型进行微调,并使用微调后的模型部署推理服务。
覆盖:
- 数据集上传
- 微调任务启动
- 微调后模型部署
- 微调后模型部署实例调用演示
准备数据集
目前平台支持alpaca和sharegpt格式
Alpaca Format
Supervised Fine-Tuning Dataset 监督微调数据集
在监督微调中, instruction 列将与 input 列连接并用作人工提示,人工提示将为 instruction\ninput 。 output 列表示模型响应。如果指定,则 system 列将用作系统提示符。
history 列是一个列表,由字符串元组组成,这些字符串元组表示历史消息中的提示-响应对。请注意,历史记录中的响应也将由模型在监督微调中学习。
{
"instruction": "human instruction (required)",
"input": "human input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["human instruction in the first round (optional)", "model response in the first round (optional)"],
["human instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]
Pre-training Dataset 预训练数据集
在预训练中,只有列 text 将用于模型训练。
[
{"text": "document"},
{"text": "document"}
]
Sharegpt Format
Supervised Fine-Tuning Dataset 监督微调数据集
与Alpacce Format相比,sharegpt格式允许数据集具有更多的角色,例如人类、gpt、观察和功能。它们显示在 conversations 列中的对象列表中。
请注意,人类和观察者应该出现在奇数位置,而 gpt 和功能应该出现在偶数位置。
[
{
"conversations": [
{
"from": "human",
"value": "human instruction"
},
{
"from": "function_call",
"value": "tool arguments"
},
{
"from": "observation",
"value": "tool result"
},
{
"from": "gpt",
"value": "model response"
}
],
"system": "system prompt (optional)",
"tools": "tool description (optional)"
}
]
sharegpt 格式不能作为预训练数据集
数据集文件夹
目前数据集文件仅支持json格式,将json文件(文件名必须为dataset.json)保存在一个文件夹(文件夹名字作为数据集的名字)中。比如下面的示例中,数据集名字为my-alpaca-demo,dataset.json中保存训练数据。

上传数据集
假设数据集文件夹是/home/kelvin/work/datasets/my-alpaca-demo。
sxwlctl(文档 https://sxwl.ai/docs/cloud/sxwlctl-guide)是算想云命令行工具,用于模型、数据集的管理。
安装sxwlctl。
wget -qO- https://sxwl-ai.oss-cn-beijing.aliyuncs.com/artifacts/tools/install.sh | bash
配置sxwlctl,把自己的AccessToken写入配置文件~/.sxwlctl.yaml
token: "eyJhb..."
使用sxwlctl,上传私有数据集。
sxwlctl upload -r dataset -d /home/kelvin/work/datasets/my-alpaca-demo
检查一下是否上传成功
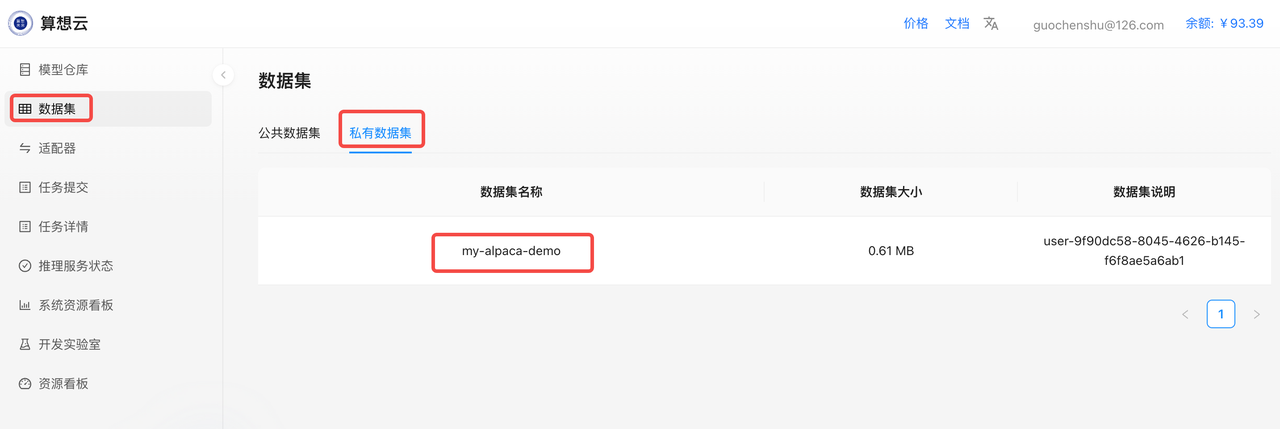
选择基底模型
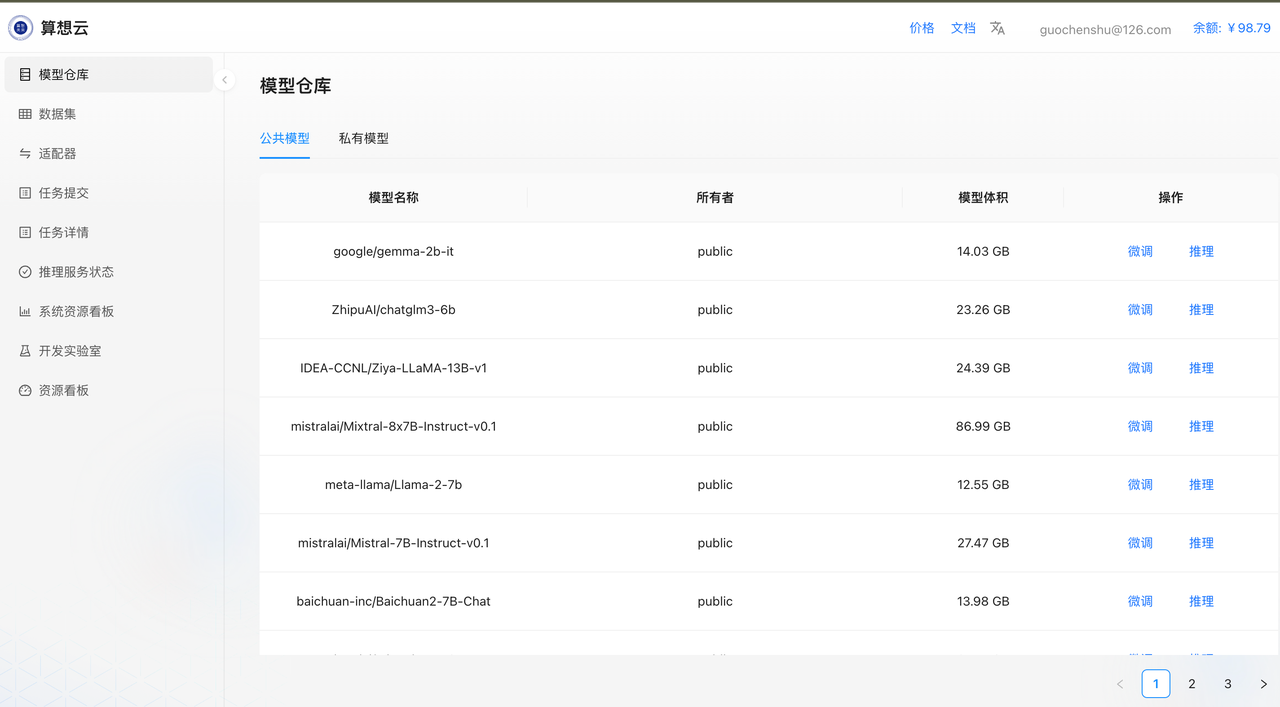
从算想云的模型仓库页面中选择一个适合本次任务的基底模型,算想云已经内置了业界主流的开源大模型,如果您想使用模型并不在列表中,可以跟算想未来团队成员(微信:guochenshu,电话: 13466636804)联系,我们会第一时间响应。这里我选择使用google/gemma-2b-it模型作为基底模型。
微调
在模型仓库页面,所选基底模型的右侧点击“微调”按钮,选择我们刚刚上传的数据集

其他参数根据自己的实际情况选择,注意选择的GPU数量越多,单位时间费用也会更高。这里我们选择保存完整模型,目前只有完整模型才能进行后续的推理。
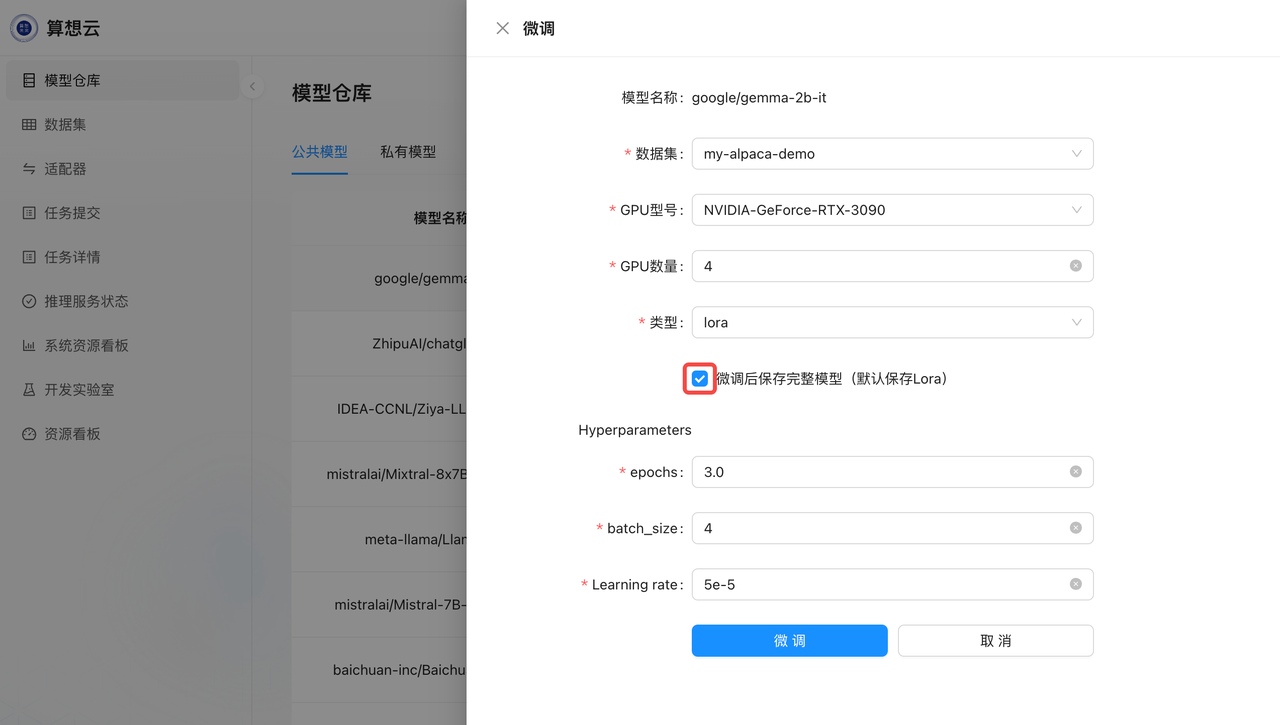
一切就绪,就可以点击“微调”按钮启动微调训练了。在任务详情页面就可以看到我们创建的任务状态。
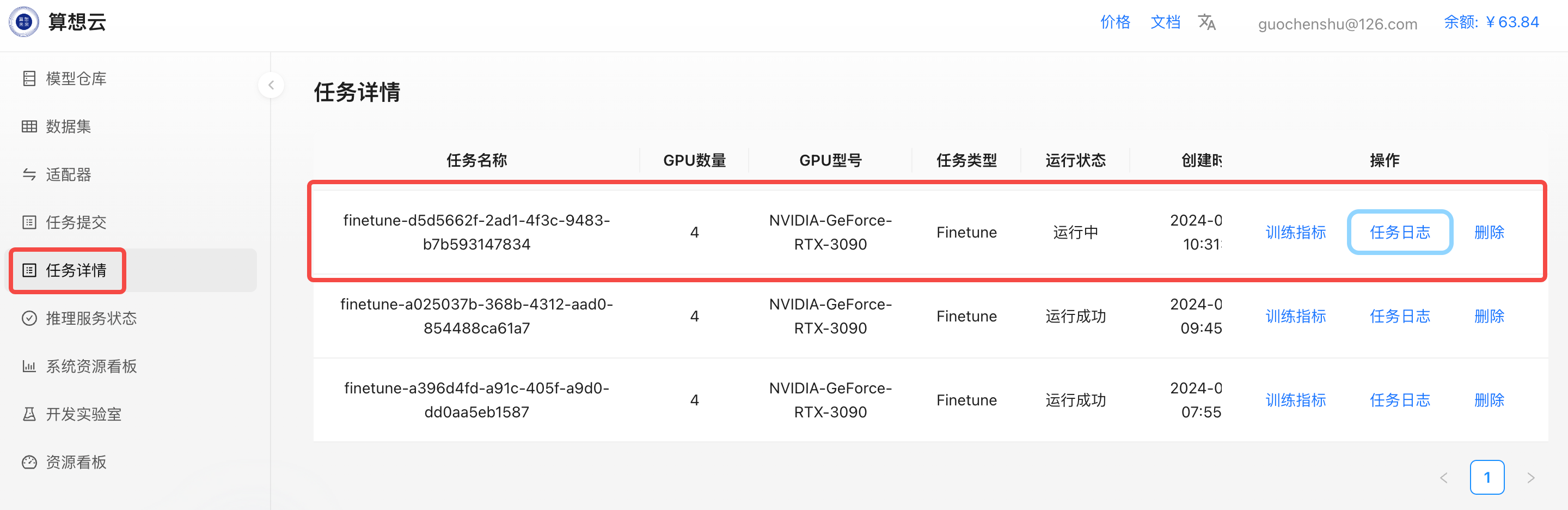
TensorBoard可以在训练指标中查看
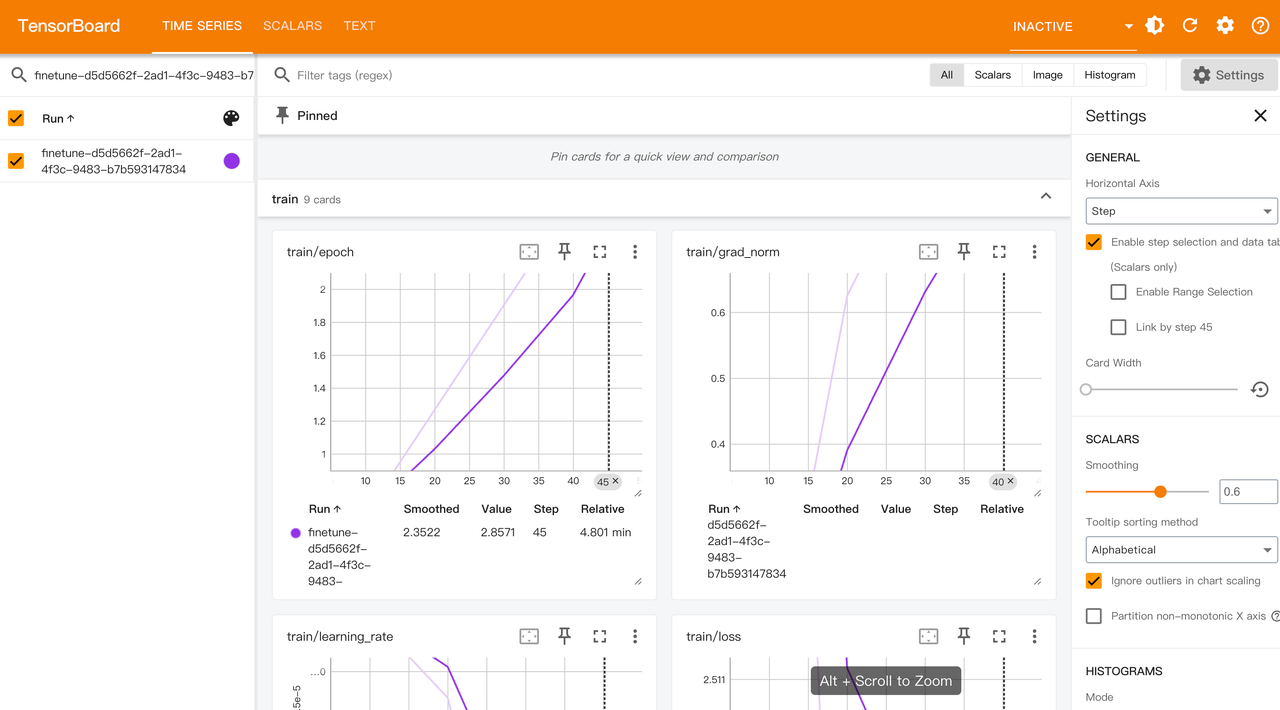
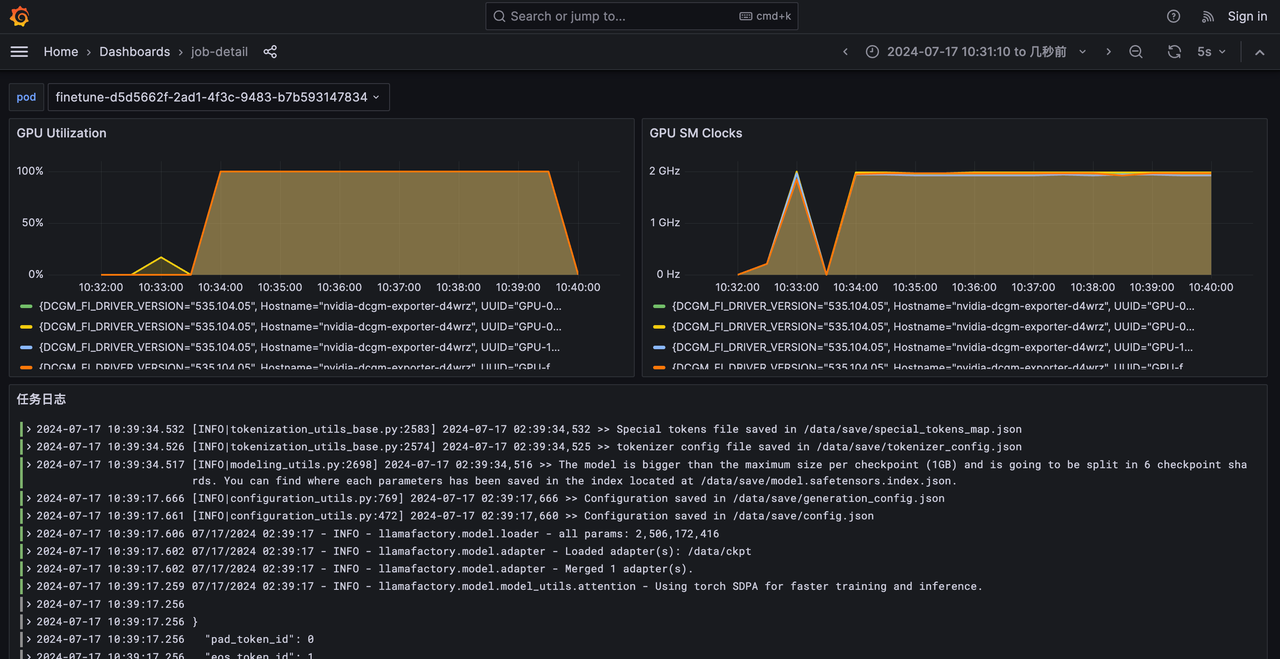
任务日志中可以查看训练的日志和GPU使用情况,用于问题排查。
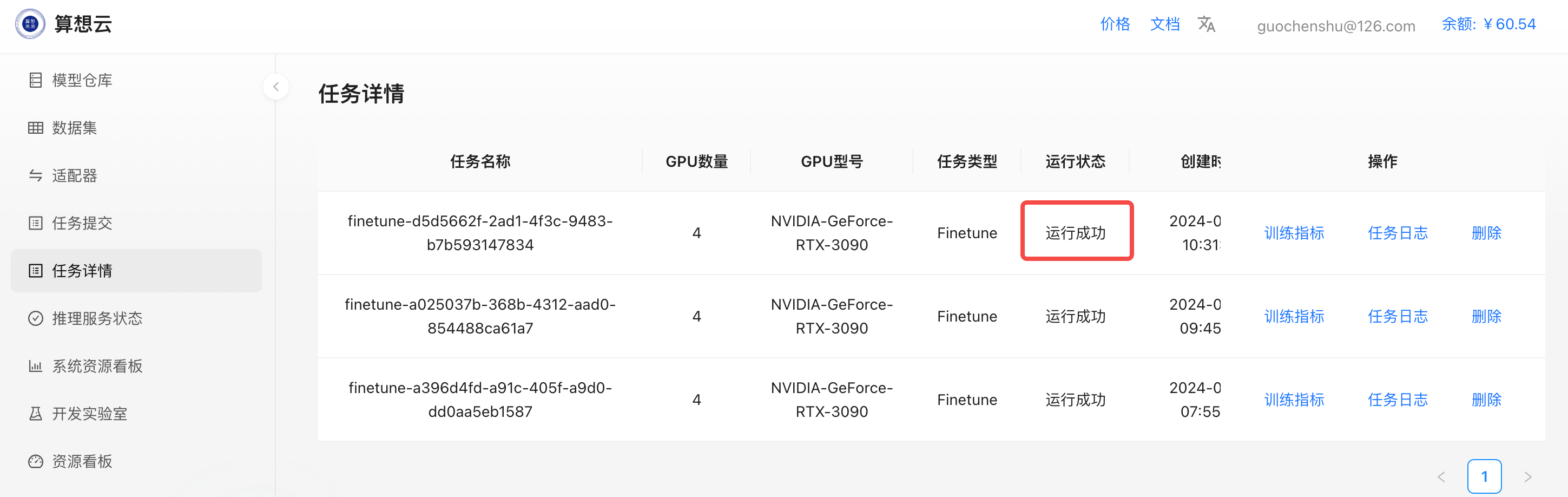
训练完成后,任务状态变为运行完成
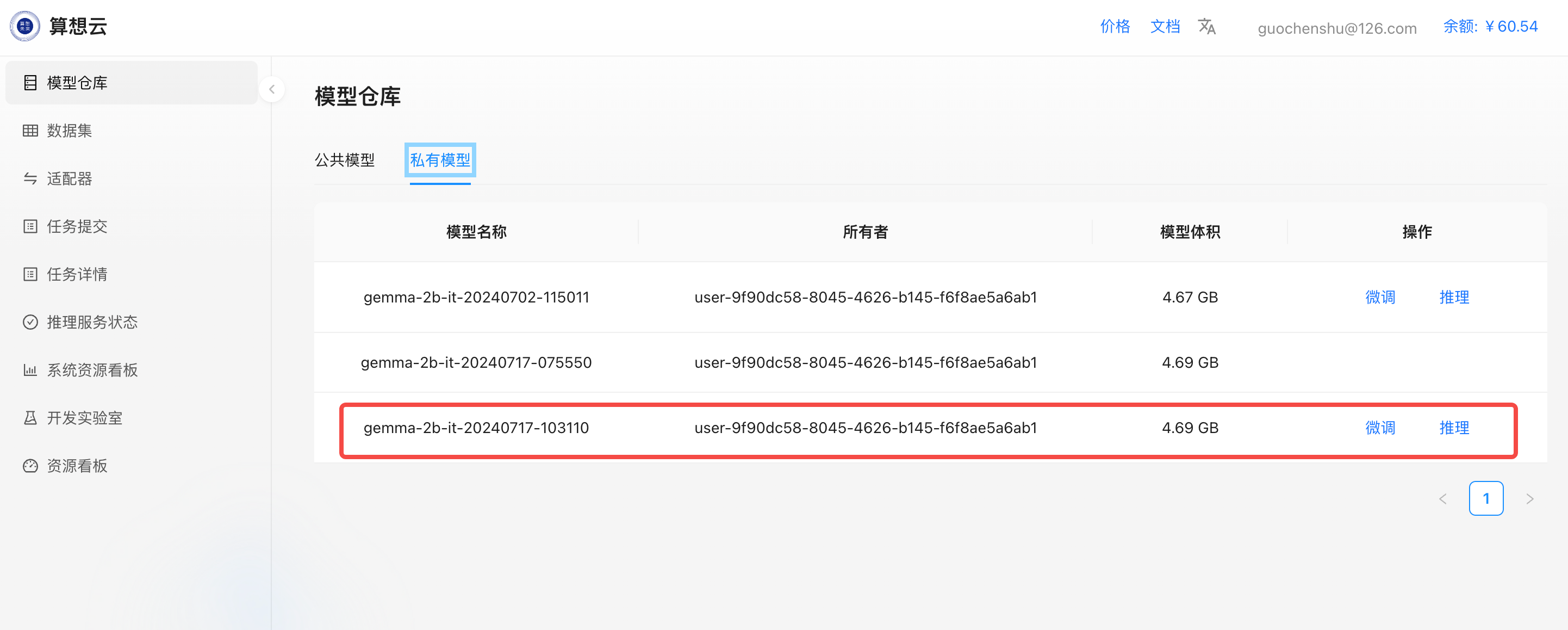
在模型仓库->私有模型中就可以看到刚才微调生成的模型。
部署推理服务
使用刚刚生成的模型,部署推理
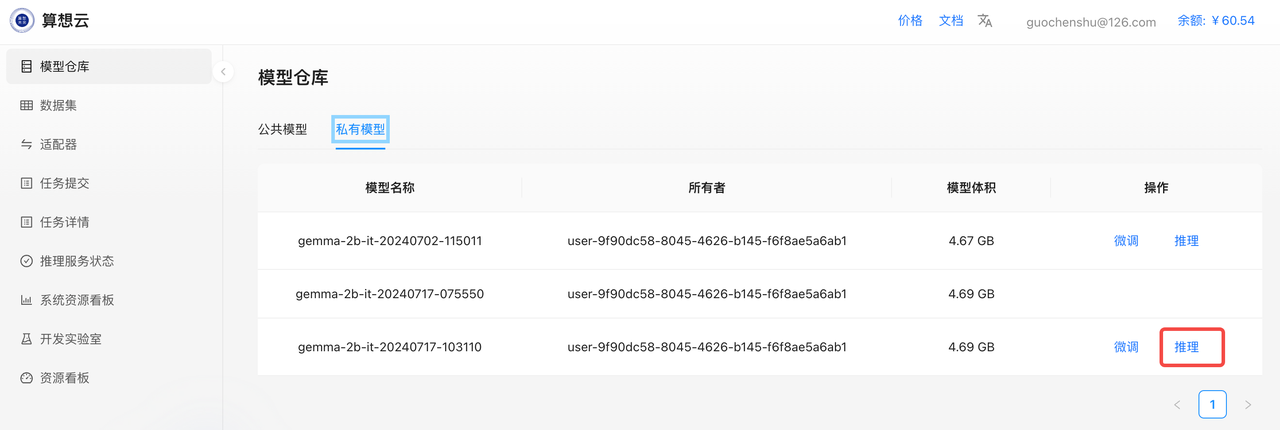
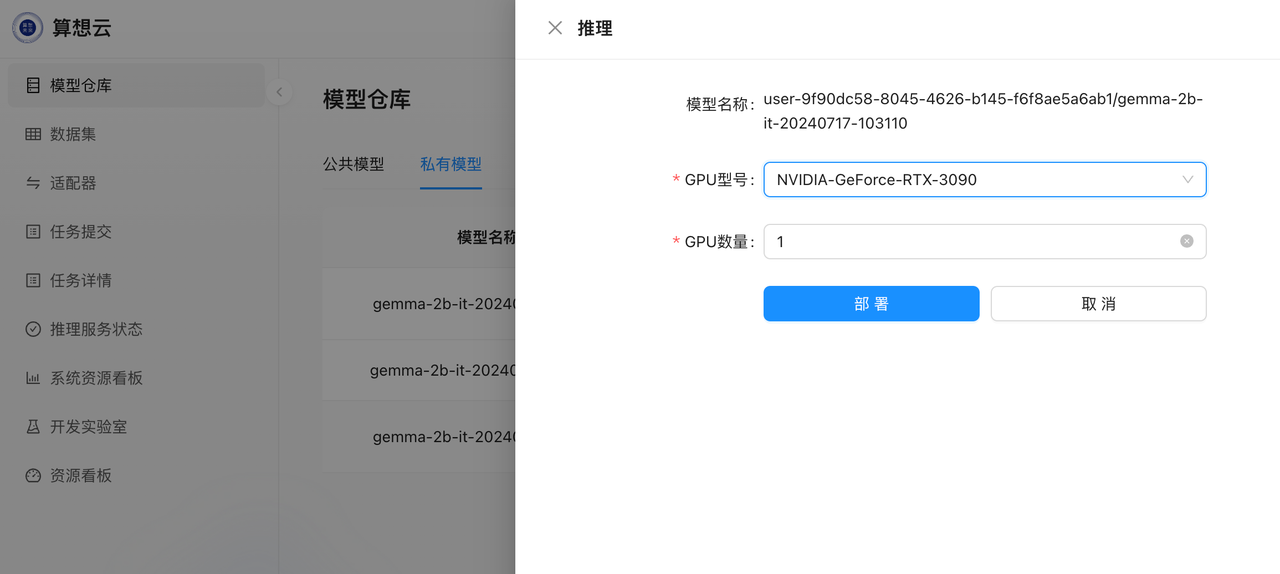
启动Chat UI
从推理服务状态
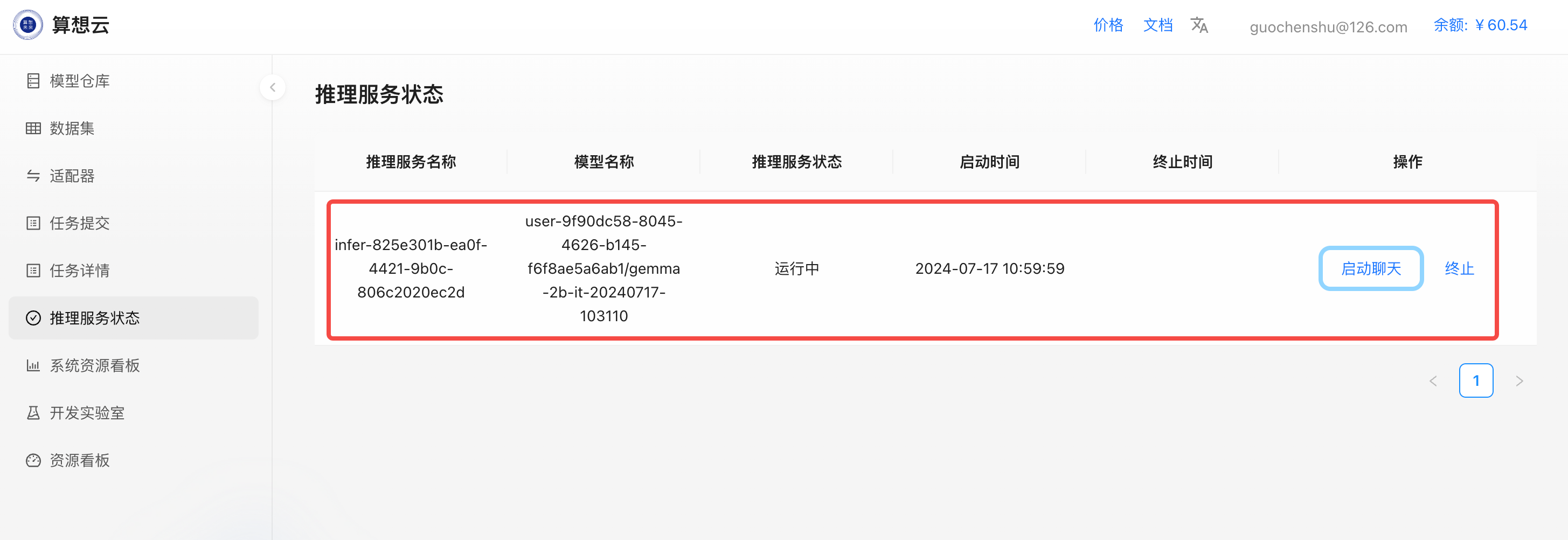
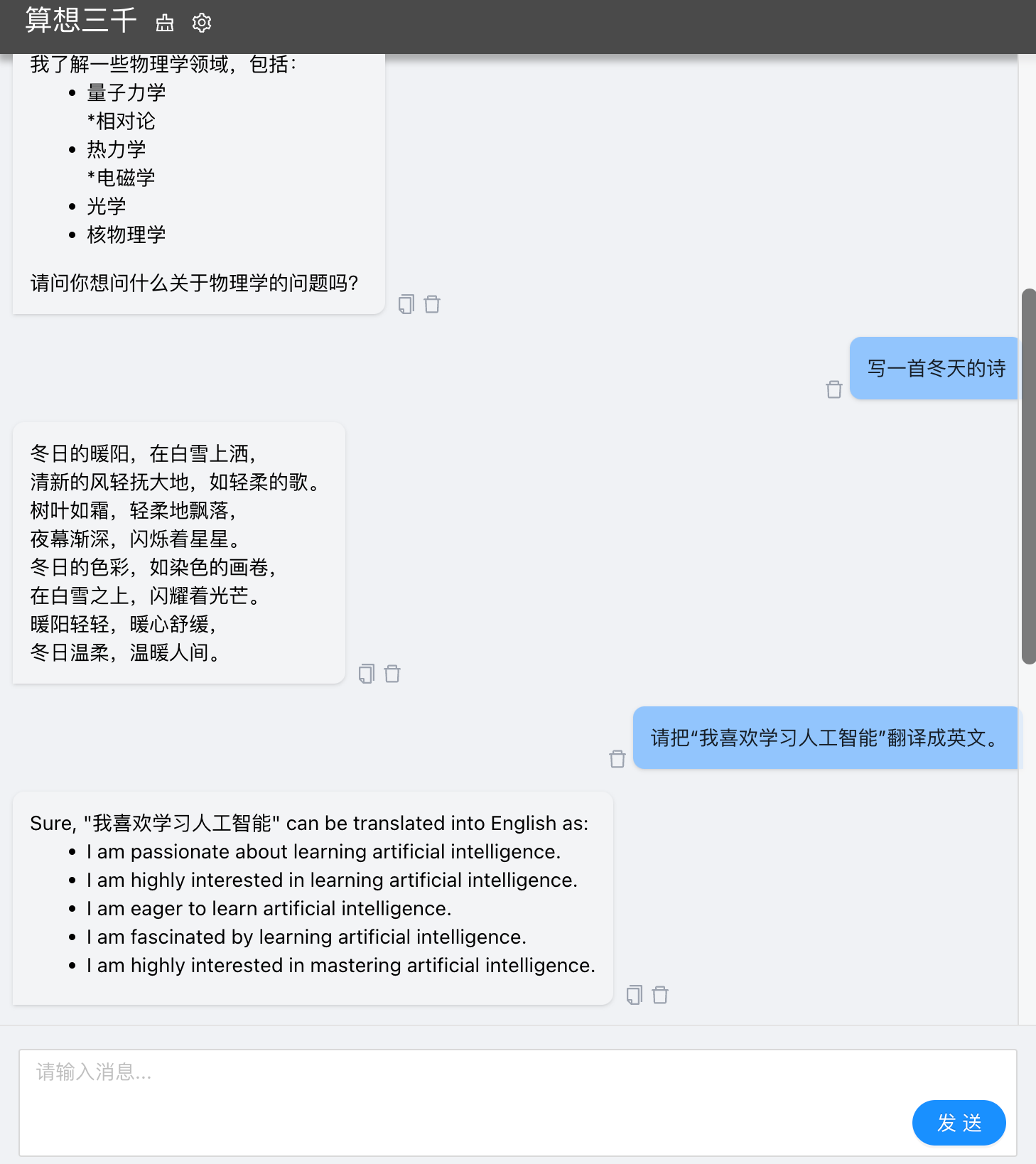
接口调用
除了chat UI,也可以使用HTTP接口来调用推理服务。我们提供OpenAI兼容的接口格式,可以参考 https://platform.openai.com/docs/api-reference/making-requests。
下面是一个调用示例
# INFER_ID是推理服务的名字,在页面上可以看到
export INFER_ID=infer-8a3c83f0-6927-4b9f-8f76-c111004a1442
curl -k -X POST https://master.llm.sxwl.ai:30004/inference/api/$INFER_ID/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "写一首冬天的诗"
}
],
"stop": [
"\nAI:",
"\nUser:"
]
}'
# 返回
{
"id": "chatcmpl-884f2ffda5e9462280261941d509ecdf",
"object": "chat.completion",
"created": 1721632837,
"model": "gpt-3.5-turbo",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "冬风轻轻吹过,\n雪花纷纷点缀着地。\n窗外的暖阳轻轻流,\n冰晶挂在枝头上。\n\n冬夜幕降临,\n星星点点,闪耀着光。\n冰天上轻柔地闪耀,\n感受寒风拂过脸颊。\n\n冬日渐消,消逝,\n天空漆黑,空洞无情。\n寒风扑鼻, reúne,\n冬日的气息,令人难忘。",
"tool_calls": null
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 14,
"completion_tokens": 102,
"total_tokens": 116
}
}